

Most applications use some relational database to store and retrieve data. As an application evolves over time, changes are necessary to underlying database structures. In addition, you may have multiple environments to support application delivery, let’s say development, test and production. Hence it makes sense to automate the build and deployment of both the application and its database structures. In this blog article, let’s discuss how FlexDeploy supports DevOps and CI/CD for database changes using the JDBC Plugin.
(Note: the FlexDeploy JDBC plugin supports Oracle, MySQL, PostgreSQL, SQL Server, SAP HANA, Sybase, and other JDBC compliant databases.)
Source code management (SCM) repositories like Git or Subversion are popular for storing application code. We recommend storing SQL files for database changes in SCM repository as well. This approach relies on developers/technical leads/administrators managing code in a SCM.
SQL files can be stored using various approaches, e.g. based on delivery release (release1.sql, release2.sql) or by individual object (countries.sql). We will examine the second approach which is finer grained to allow for easy comparison over time in source code repository. We also recommend you qualify objects with schema name, so files can be executed with common administrative users at deployment time.
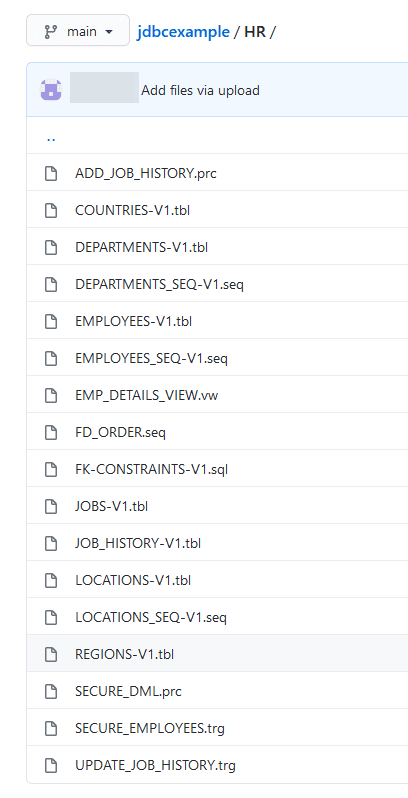 We are using various extensions like tbl (table), trg (trigger), seq (sequence), etc. Also, note that some files have -V1 in the name, this is used for objects that can not be re-executed, hence if there is change needed you can create another file with -V2 in the name.
We are using various extensions like tbl (table), trg (trigger), seq (sequence), etc. Also, note that some files have -V1 in the name, this is used for objects that can not be re-executed, hence if there is change needed you can create another file with -V2 in the name.
There are some complexities with database change deployments, for example order of execution is very important (table must be created first before its trigger), and we also need to make sure that some scripts are only executed once per environment (i.e. create table can be only done once as next attempt will fail).
FlexDeploy provides multiple options to control execution order.
- Using file extension – customizable extension names to enforce execution order.
- Alphabetical sort – file name is used to control execution order, i.e. execute V1 file first and then V2.
- Customized order using sequence file in code repository.
FlexDeploy partial deployment capability also makes sure that a file is executed only once in each environment, which ensures that create table is only done once. But in order to apply any changes to a table that was already created, you need to create V2 version of SQL with just alter commands.
FlexDeploy blueprints can be used to speed up and adopt best practices based configuration of the FlexDeploy Projects. We will use SQL Scripts blueprint for this purpose.
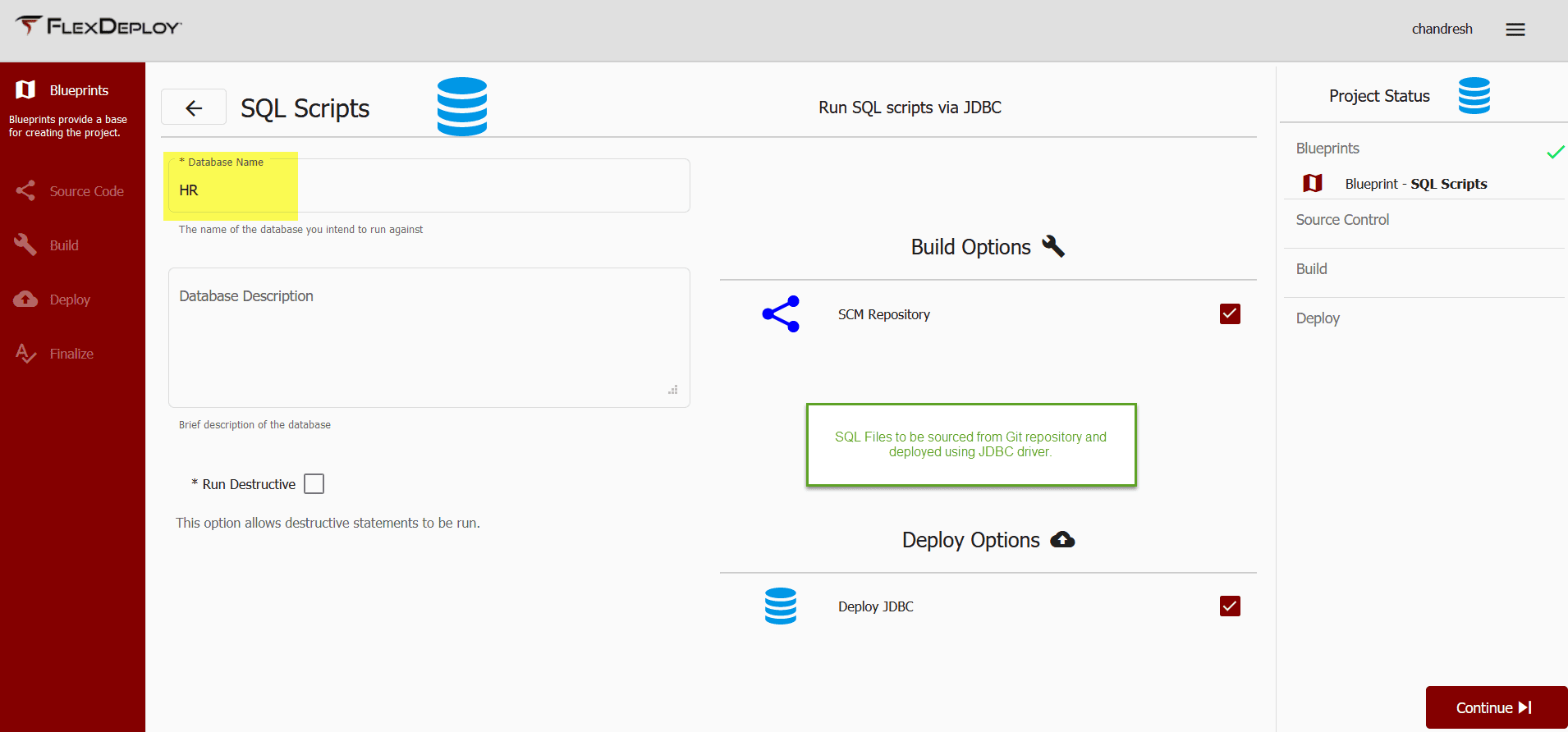
 Next, we will provide a database name.
Next, we will provide a database name.
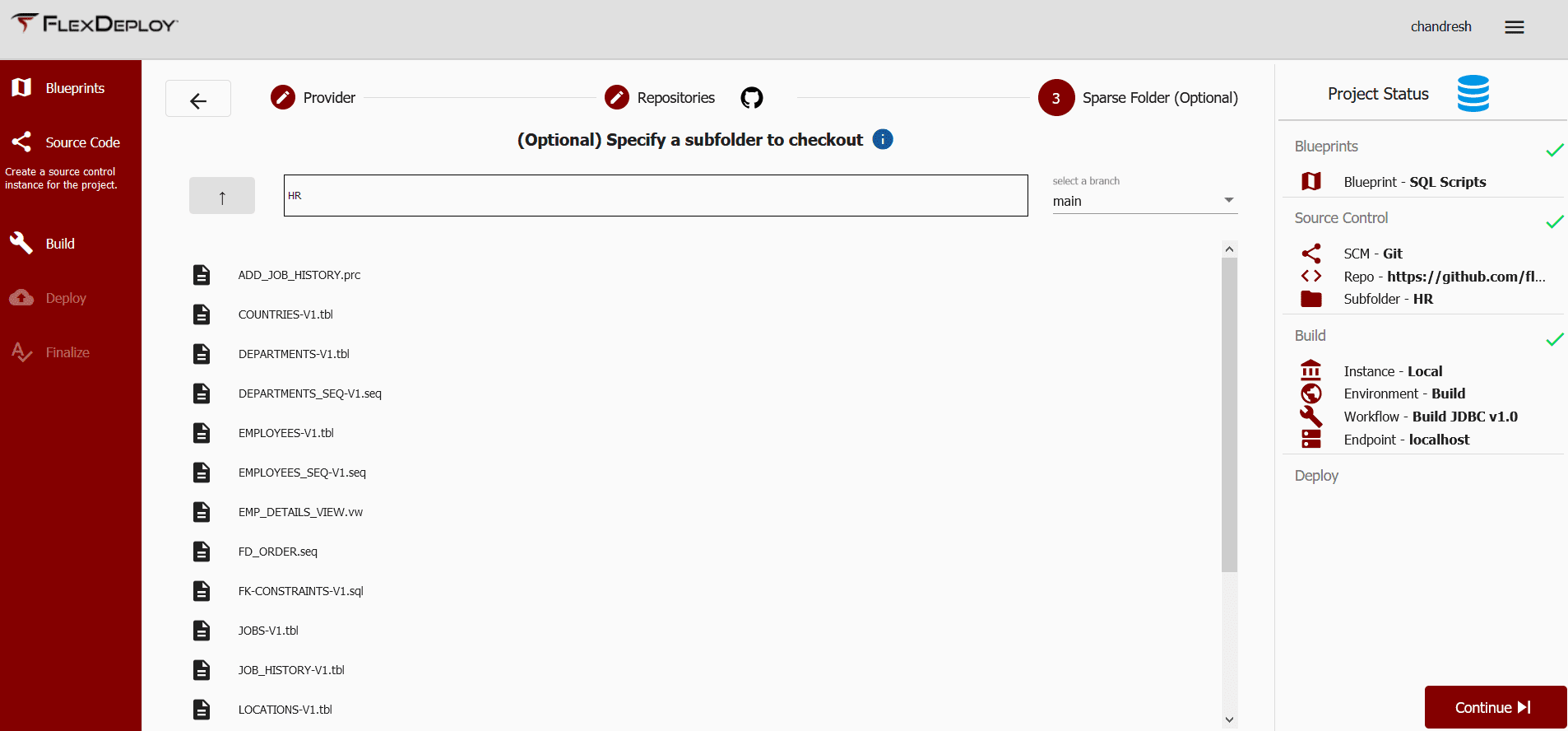
 N0w select the Git repository location where we have stored various SQL files.
N0w select the Git repository location where we have stored various SQL files.
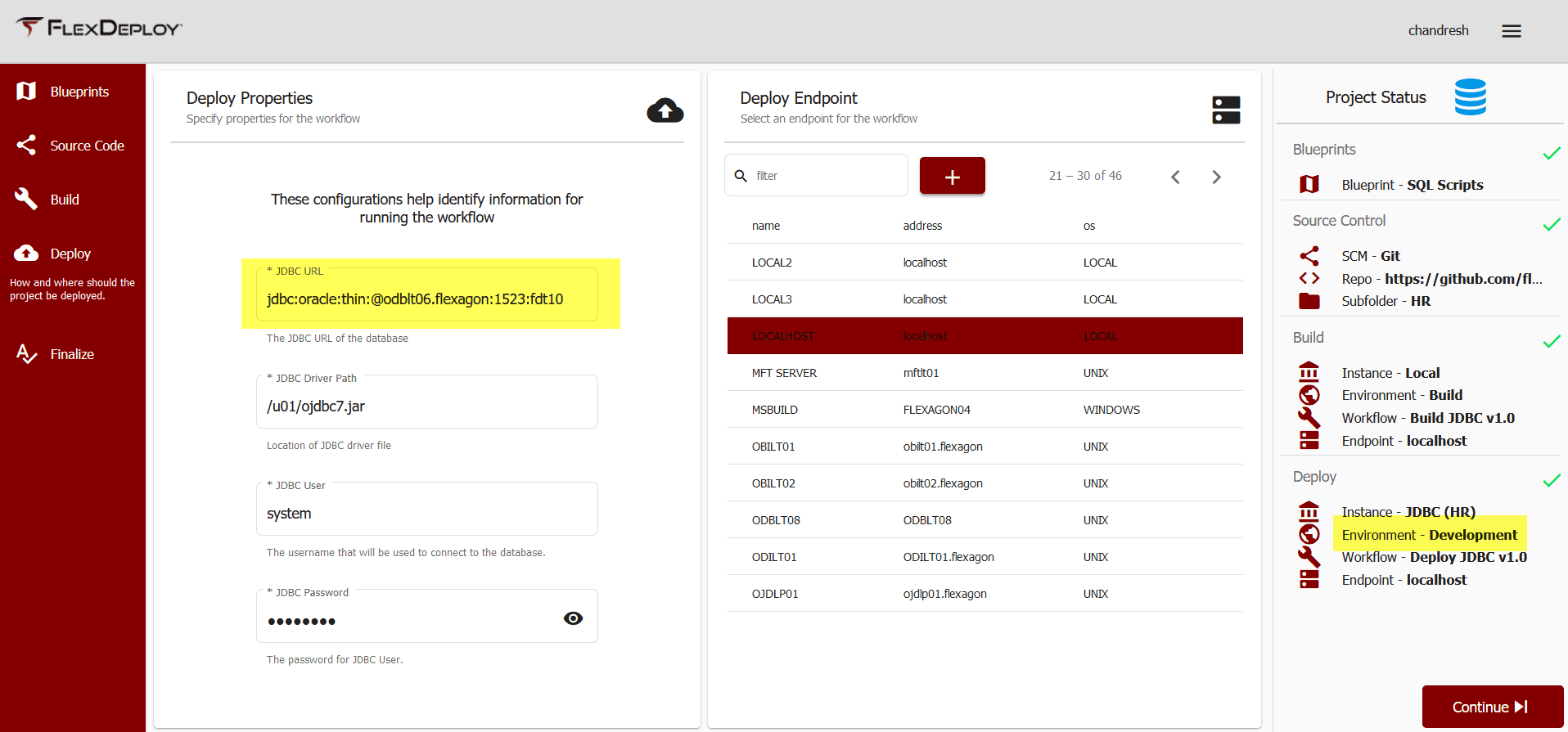
 A blueprint is used as a quick start and, in this case, it will set up the development environment, and other environments can be configured later very easily. The wizard based blueprint will guide you through the process where you will provide development environment details like JDBC URL, User, and Password. You can use system or any other administrative user which will be used to create objects.
A blueprint is used as a quick start and, in this case, it will set up the development environment, and other environments can be configured later very easily. The wizard based blueprint will guide you through the process where you will provide development environment details like JDBC URL, User, and Password. You can use system or any other administrative user which will be used to create objects.
 Once finished, the blueprint will create workflows, topology, and project configurations.
Once finished, the blueprint will create workflows, topology, and project configurations.
 Now, like any other project in FlexDeploy, you can perform automated build and deploy. Let’s execute build first. As this is a partial deployment project, you can either build all files or just some selection of files. We will go ahead and perform the build of all files.
Now, like any other project in FlexDeploy, you can perform automated build and deploy. Let’s execute build first. As this is a partial deployment project, you can either build all files or just some selection of files. We will go ahead and perform the build of all files.
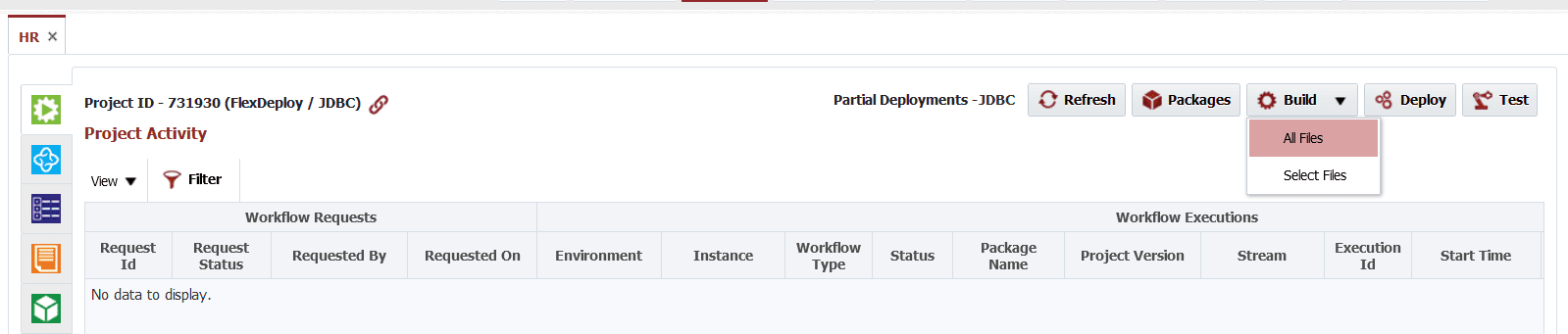 As build is running, let’s look at the list of files as discovered by FlexDeploy. Note that they are sequenced as per extension and custom sequence file (FD_ORDER.seq). We had committed FD_ORDER.seq file in the Git repository.
As build is running, let’s look at the list of files as discovered by FlexDeploy. Note that they are sequenced as per extension and custom sequence file (FD_ORDER.seq). We had committed FD_ORDER.seq file in the Git repository.
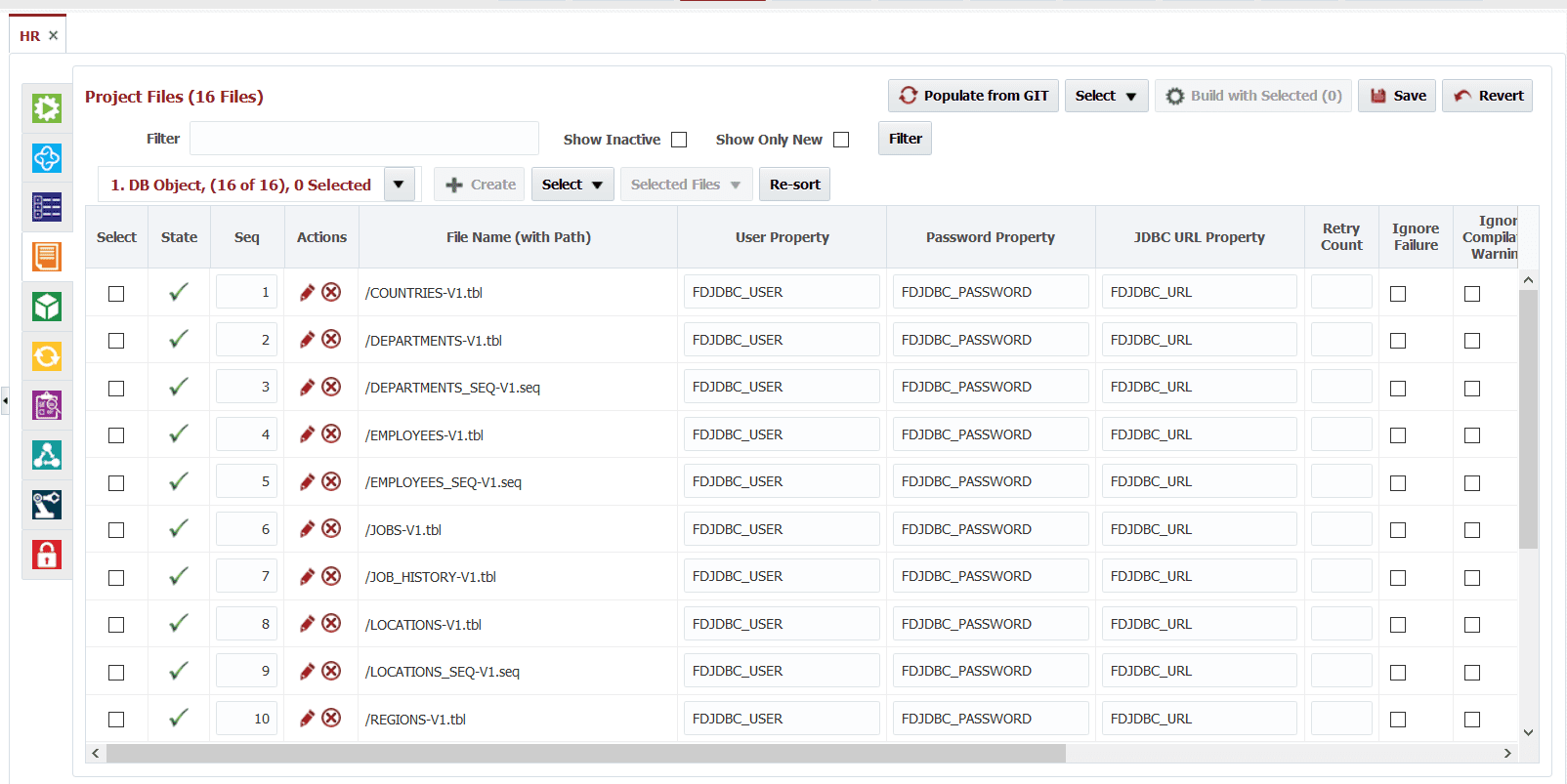 When the build is completed, FlexDeploy will version the artifacts in an internal artifact repository. Now you can deploy this version to various environments and it does not get impacted by changes in the Git repository. If you change files in the Git repository you will need to perform a new build, or you can setup a Webhook to perform build and deploy automatically.
When the build is completed, FlexDeploy will version the artifacts in an internal artifact repository. Now you can deploy this version to various environments and it does not get impacted by changes in the Git repository. If you change files in the Git repository you will need to perform a new build, or you can setup a Webhook to perform build and deploy automatically.
 Build is essentially a capture of files from Git in this case. Let’s try deployment to the Development environment as we had configured that via blueprint.
Build is essentially a capture of files from Git in this case. Let’s try deployment to the Development environment as we had configured that via blueprint.
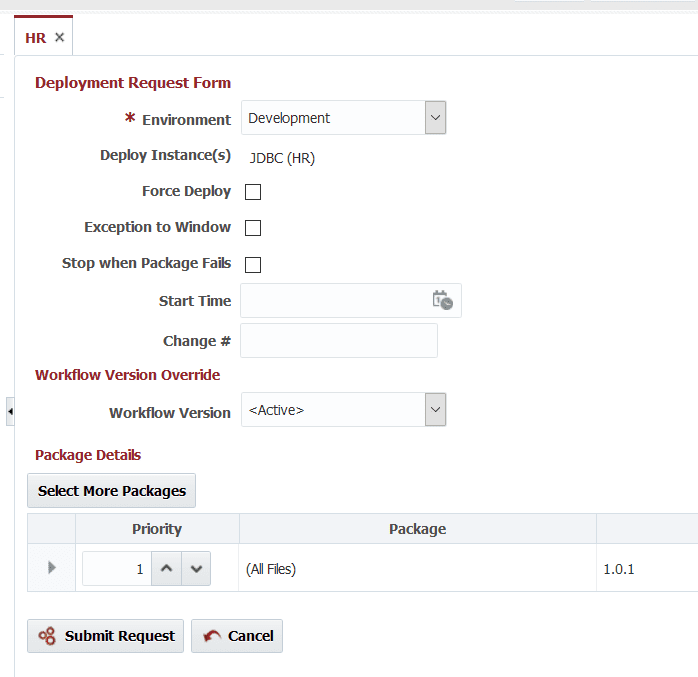 A FlexDeploy build workflow will deploy files that have changed since last deployment. As this is our first deployment, it will deploy all files that are part of build artifacts.
A FlexDeploy build workflow will deploy files that have changed since last deployment. As this is our first deployment, it will deploy all files that are part of build artifacts.
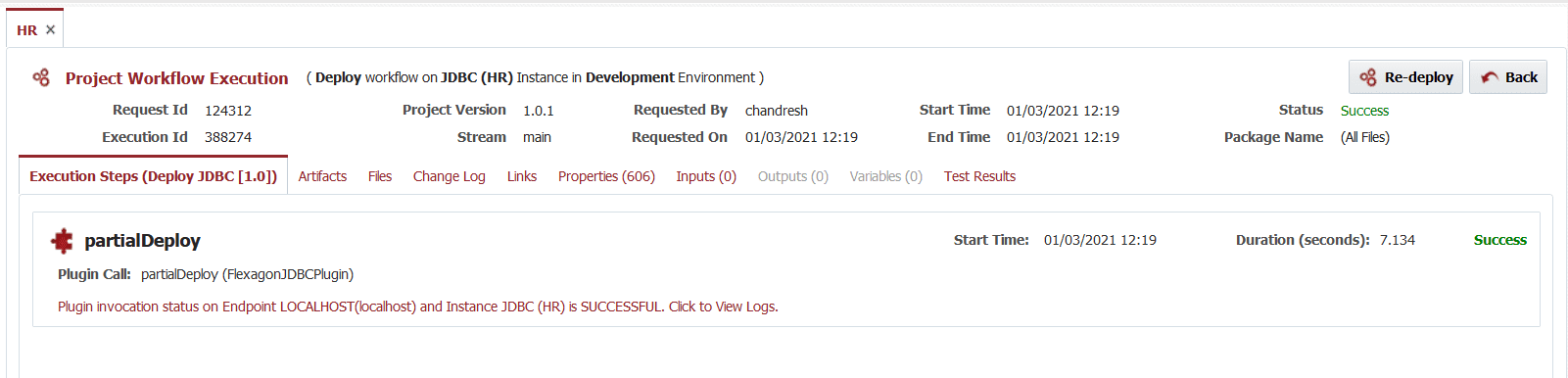 Similar to other plugins provided by FlexDeploy, execution logs are visible in the FlexDeploy UI and in case of failure you can make necessary adjustments. Let’s see objects in our database and make sure they are created.
Similar to other plugins provided by FlexDeploy, execution logs are visible in the FlexDeploy UI and in case of failure you can make necessary adjustments. Let’s see objects in our database and make sure they are created.
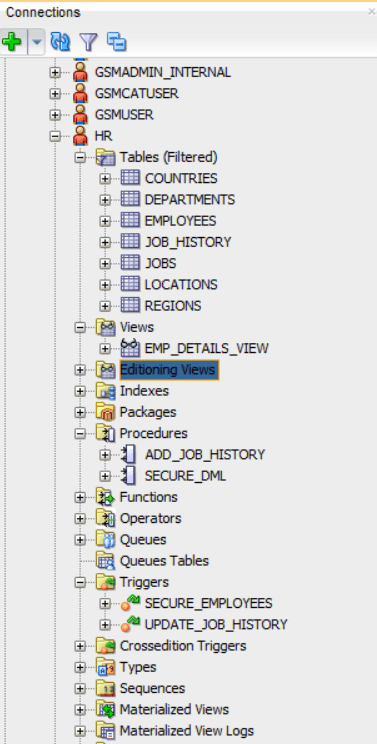 Everything is automatically deployed in our development environment.
Everything is automatically deployed in our development environment.
Now if you want to make change for COUNTRIES table, then create new file COUNTRIES-V2.tbl with necessary alter commands and commit to the Git repository. Either set up automated build & deploy or perform manually and your changes will be automatically applied to development environment. Note that in this particular scenario, only COUNTRIES-V2.tbl will be executed as other files were already deployed. But if you want to make change to UPDATE_JOB_HISTORY trigger then just update UPDATE_JOB_HISTORY.trg file and commit it. As triggers use Create or Replace syntax, it is possible to re-execute them as necessary.
Here we just discussed individual deployment of SQL files. FlexDeploy also allows combining various changes such as the application in a release and deploying them in appropriate sequence with necessary change control (schedule, approval etc.). To see an example of this in action, you can read the FlexDeploy Loves APEX blog series which shows how the APEX application along with the database object changes can be deployed together in a release.
If you want to view other information on automating database related changes, see the following FlexDeploy for Database page.


